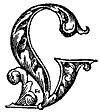|
Как известно, djvu-книги представляют собой особым образом сжатые изображения страниц издания-оригинала. По этой причине если в исходной книге имелись рисунки, то необходимости выделения их из текста не возникает. Совсем другое дело, если создаётся pdf- или chm-книга с распознанным текстом, но в ней должны присутствовать изображения, иллюстрирующие её содержимое. В этом случае необходимо выделить из сканов страниц оригинала все рисунки, схемы, диаграммы и дополнительно их обработать. Здесь снова понадобится графический редактор – “Photoshop” или “GIMP”. На мой взгляд, наиболее оптимальным при подготовке иллюстраций является следование принципам, которые используются в веб-дизайне при подготовке файлов изображений, размещаемых в Интернете. В подавляющем большинстве случаев это файлы форматов JPEG, GIF или PNG. Сказанное вовсе не означает, что можно просто вырезать рисунки, диаграммы, графики из сканов страниц книги и сохранять их в одном из указанных форматов. К этому желательно подходить рационально. Во-первых, поскольку страница отсканирована скорее всего с разрешением 300 dpi (а может быть и больше), то в пиксельном выражении все рисунки будут довольно большими. В связи с этим необходимо уменьшить их ширину и высоту, приблизив размеры рисунка при отображении на компьютерном мониторе к фактическим, то есть к тем, какие он имел в оригинале на книжной странице. Следует оговориться, что уменьшать рисунки нужно осмотрительно – иногда они содержат много мелких деталей, которые при изменении размера могут просто потеряться, в результате информативность изображения снизится. Во-вторых, для выделенного из скана рисунка может понадобиться цветокоррекция (если она не была проведена ранее – см. пункт «Обработка сканов») для улучшения его вида. В-третьих, перед сохранением готового файла с картинкой для дополнительного уменьшения его размера нужно оптимизировать изображение. Например, в Photoshop’е для этого служит инструмент File → Save for Web... (Файл → Сохранить для Web...). Подробный рассказ о тонкостях работы с ним выходит за пределы тематики настоящего пособия, поэтому рекомендую изучить этот вопрос самостоятельно, используя имеющуюся в Интернете информацию. Если книжная страница отсканирована в монохромном режиме, то имеющиеся на ней и предварительно «вырезанные» из скана рисунки можно «пережимать» следующим образом:
При действии описанным способом получается файл довольно небольшого размера. На Рисунке 6 показан пример исходного рисунка и результат такой его обработки.
Рисунок 6. Исходное изображение на скане страницы (слева) и оно же после пережатия (справа). В качестве примера использована буквица на с. 6 издания: Живое слово. Книга для изучения родного языка. Часть II / Сост. Острогорский А.Я. 10-е изд. – Петроград: Типография Тренке и Фюсно, 1916. – 399 с. Во многих книгах встречается представление данных в виде таблиц. В электронных же версиях таких изданий часто эти таблицы вставлены в текст книги в виде рисунков (фрагментов сканов), обработанных аналогично тому, как это описано выше. Некоторые OCR-программы (например, “CuneiForm”) умеют определять, что на скане имеется таблица и позволяют сохранить распознанную информацию именно в виде таблицы (электронной). И хотя она, скорее всего, будет нуждаться в дополнительной проверке её данных и форматировании при помощи пригодной для этого программы (MS “Word”, “Excel” и т. п.), после распознавания табличная информация станет, как и остальной текст, «компьютерно-живой» – её данные смогут быть легко переданы (скопированы) во многие другие программы. Если таблиц в книге немного и они не очень объёмные, то их можно набрать вручную, что также обеспечит их «компьютерную живость» в готовой книге. На мой взгляд, такой подход более предпочтителен, нежели просто вставка сканированного изображения таблицы в оцифрованную книгу. Ещё одна разновидность иллюстративного материала, встречающаяся в книгах – это различные схемы (например, блок-схемы алгоритмов в учебниках по программированию). Если планируется создание электронной книги в формате PDF, а схем, подобно вышеописанному случаю с таблицами, не очень много и они довольно простые, то имеет смысл не оставлять каждую из них растровой картинкой, а перерисовать, представив в виде векторного рисунка. Создать его можно при помощи любого редактора векторной графики, которым вы владеете (LO “Draw”, например). Вполне могут сгодиться и штатные средства работы с векторной графикой, имеющиеся в MS “PowerPoint”, чтобы нарисованную вручную схему сохранить затем в формате WMF. |